Pixels
Each pixel stores intensity information for one or more channels, depending on the colour scheme.
The resolution of an image is given by the number of pixels along width \times height, e.g.,
1920×1080.

Colour schemes: greyscale
- Typically represented as 0–255 (8-bit), where 0 = black, 255 = white.
- No colour information, only lightness/darkness.

Colour schemes: RGB
- Each channel is usually 8-bit (0 – 255), representing the intensity of that colour component.
- Variants:
- RGBA: Adds an Alpha channel for transparency.
- BGR: Some libraries (like OpenCV) use this channel order.

CIFAR datasets: Cat vs. Dog
We extract the cat and dog images from the dataset, using 5,000 for training and 2,000 for testing in each class.

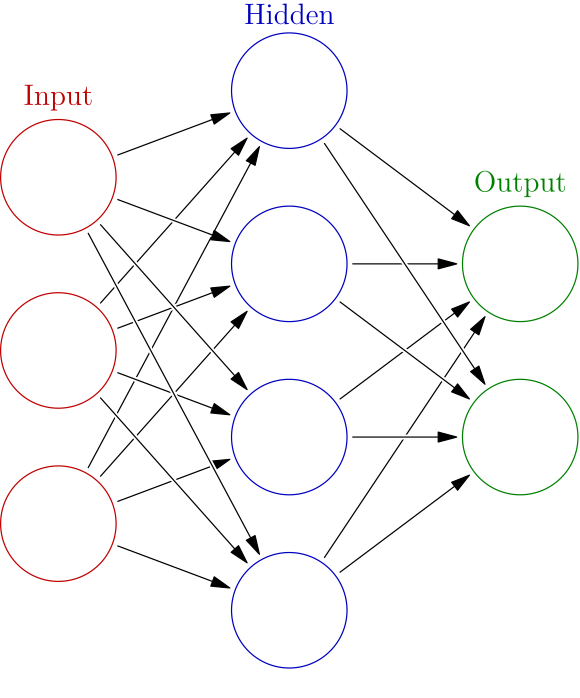
Neural networks
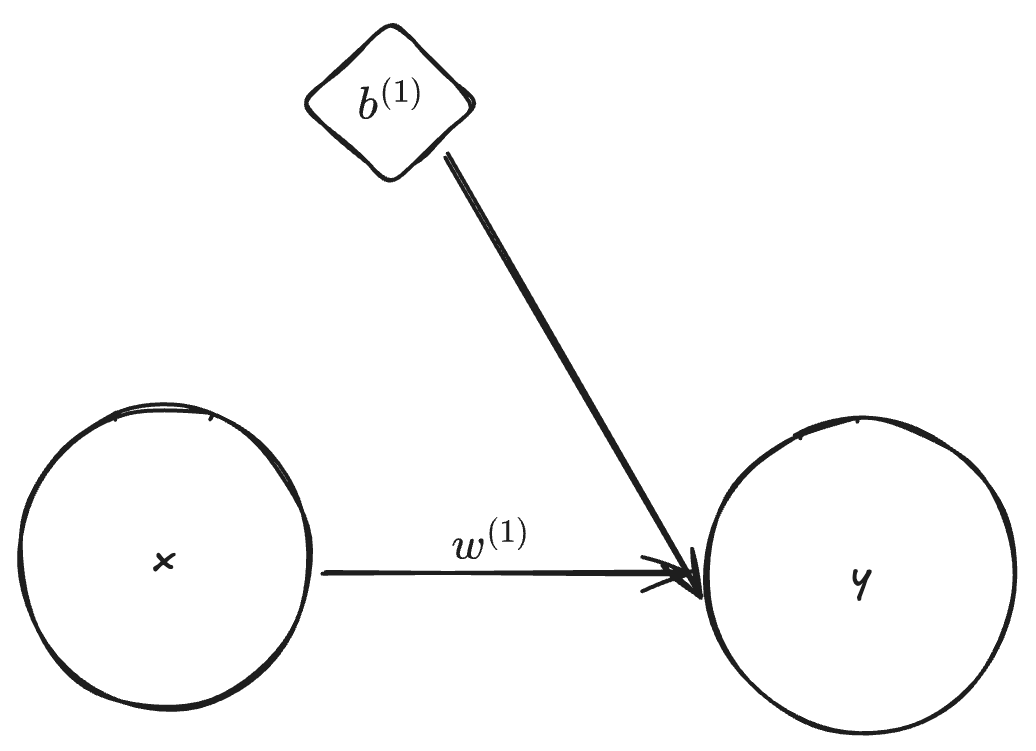
Simple linear regression
By setting the dimension of \mathbf{x}, \mathbf{y} and \mathbf{b}^{(1)} to one, L = 1 and f^{(1)}(z) = z, we obtain
y = w^{(1)} x + b^{(1)}.
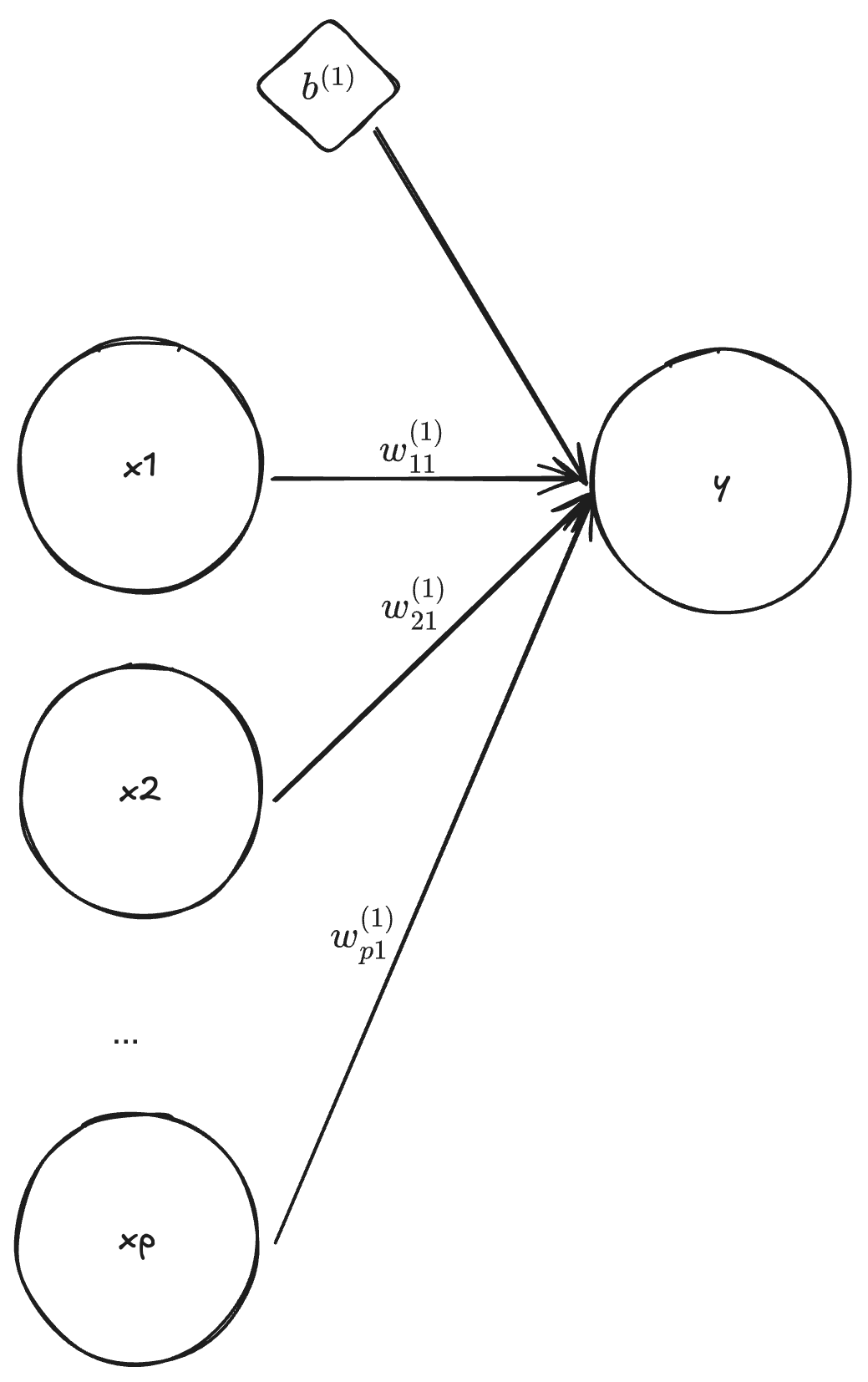
Multiple linear regression
By setting the dimension of \mathbf{x} to p, the dimension of \mathbf{y} and \mathbf{b}^{(1)} to one, L = 1 and f^{(1)}(z) = z, we obtain
y = \mathbf{w}^{(1)} \mathbf{x} + b^{(1)}.
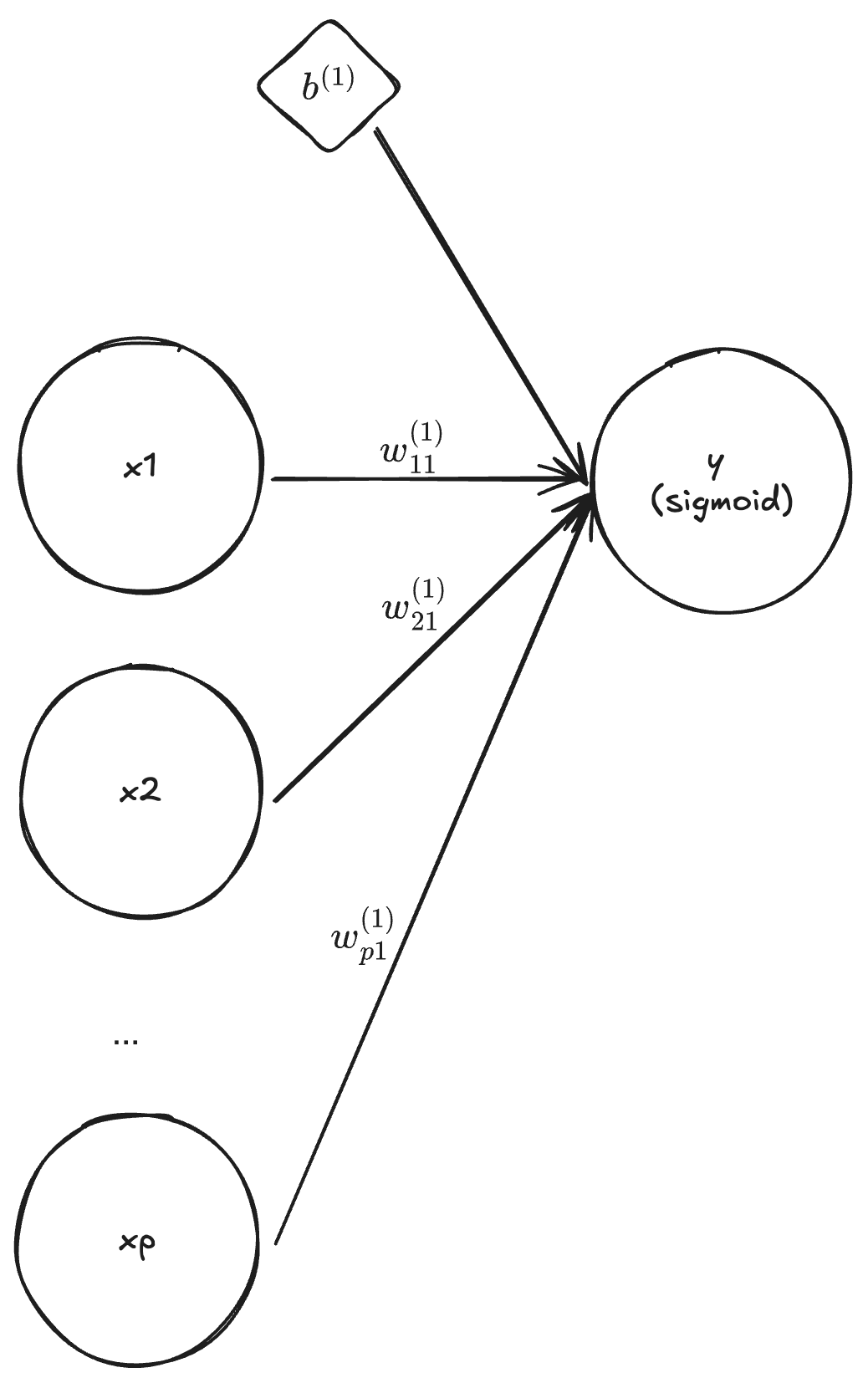
Logistic regression
By setting the dimension of \mathbf{x} to p, the dimension of \mathbf{y} and \mathbf{b}_1 to one, L = 1 and f^{(1)}(z) = \frac{e^z}{1 + e^z}, we obtain
y = f^{(1)}(\mathbf{W}^{(1)} \mathbf{x} + b^{(1)}) = \frac{e^{\mathbf{W}^{(1)} \mathbf{x} + b^{(1)}}}{1 + e^{\mathbf{W}^{(1)} \mathbf{x} + b^{(1)}}}.
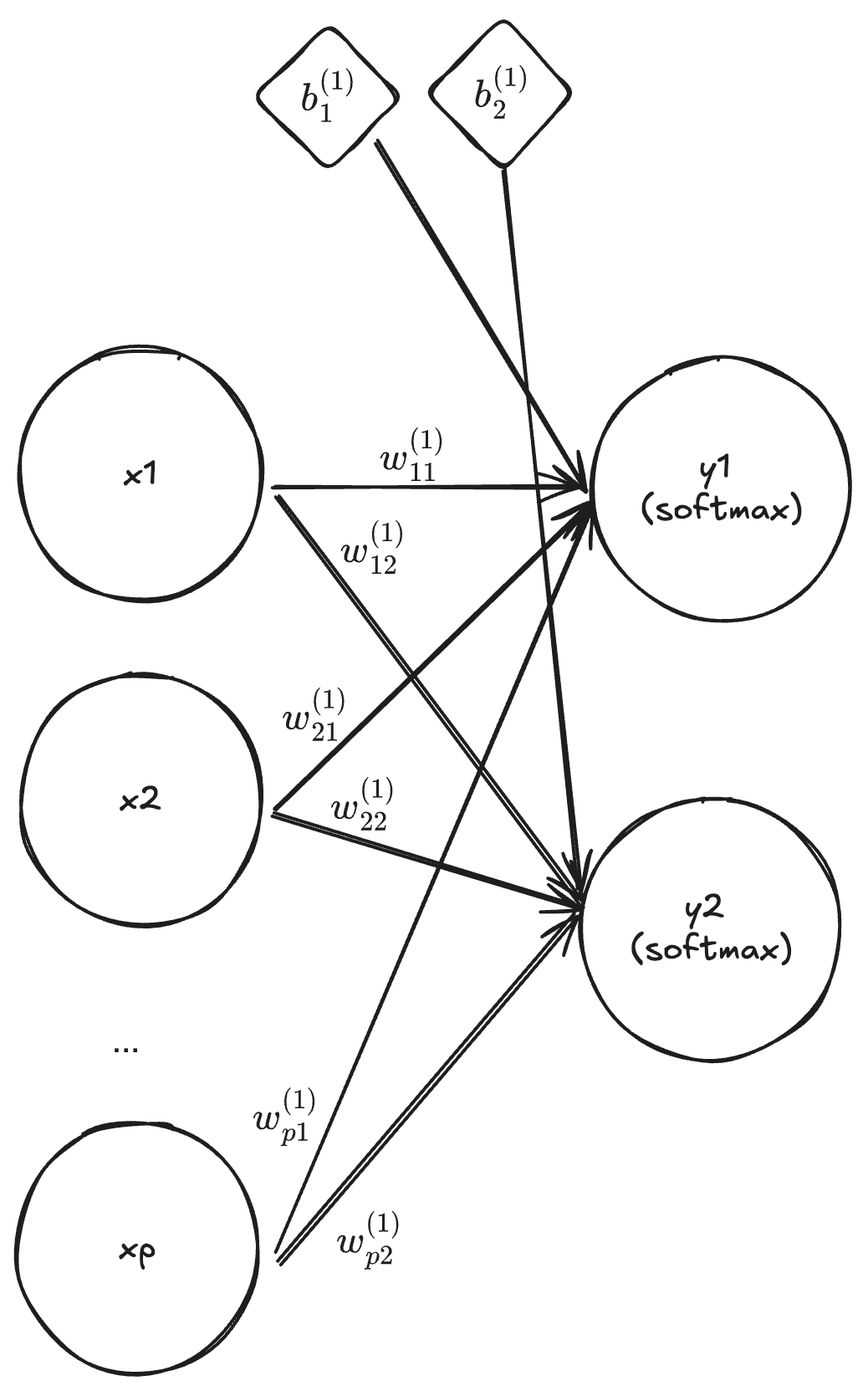
Multinomial logistic regression
By setting the dimension of \mathbb{x} to p, the dimension of \mathbf{y} and \mathbf{b}_1 to K, L = 1 and f^{(1)}(\mathbf{z}) = \frac{\exp(\mathbf{z})}{\sum_{k=1}^{K}\exp({z_k})}, we obtain
\mathbf{y} = f^{(1)}(\mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}) = \frac{\exp(\mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)})}{\sum_{k=1}^{K} \exp\big(\mathbf{W}^{(1)} \mathbf{x} + b^{(1)}_{k}\big)}.
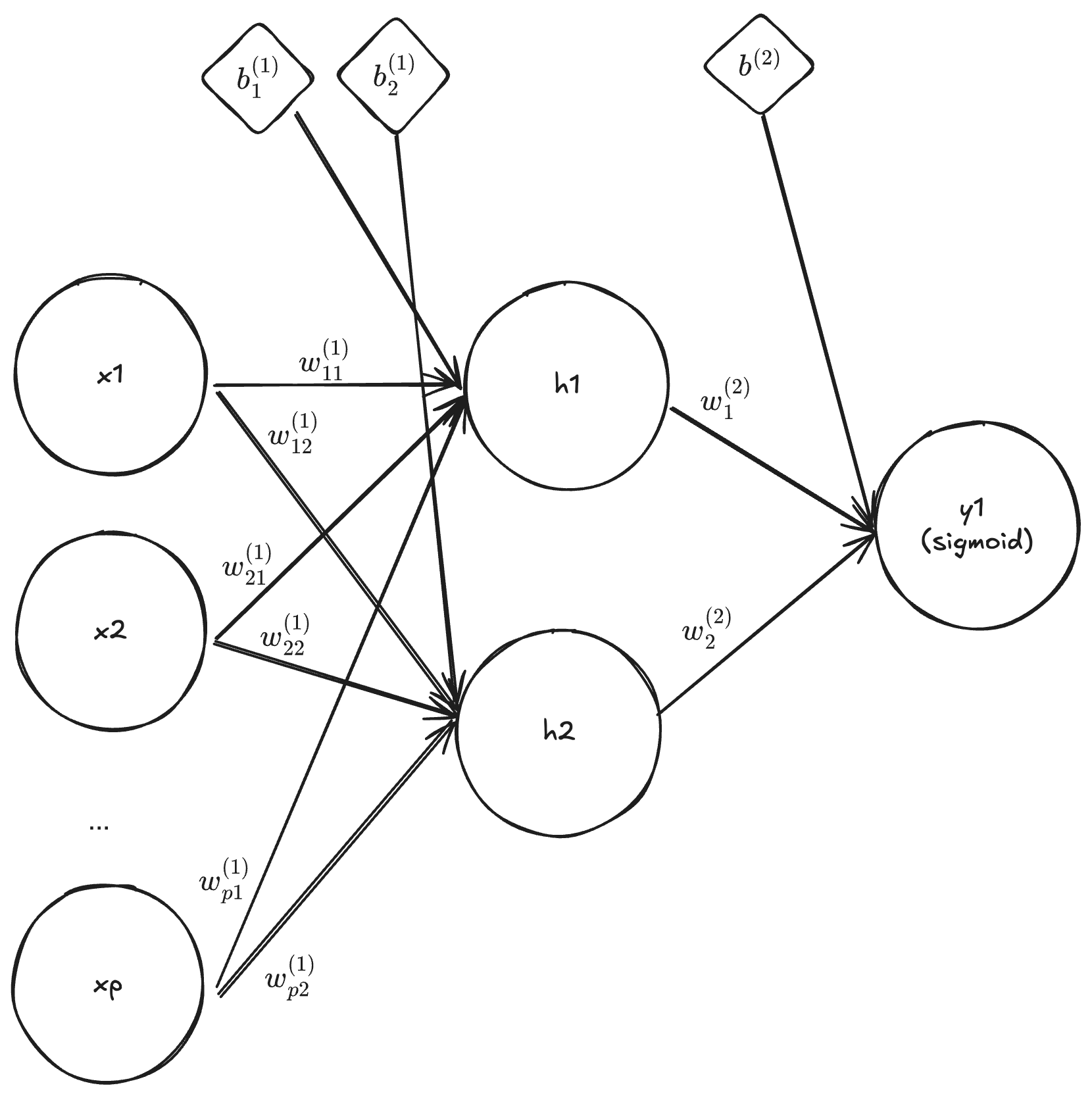
Multi-layer binary classifier
By setting the dimension of \mathbb{x} to p, the dimension of \mathbf{y} and \mathbf{b}_1 to one, L = 2, f^{(1)}(z) = z and f^{(2)}(\mathbf{z}) = \frac{\exp(\mathbf{z})}{\sum_{k=1}^{K}\exp({z_k})}, we obtain
\mathbf{h} = \mathbf{w}^{(1)} \mathbf{x} + \mathbb{b}^{(1)}, \quad \mathbf{y} = f^{(2)}(\mathbf{W}^{(2)} \mathbf{h} + b^{(2)}) = \frac{e^{\mathbf{W}^{(2)} \mathbf{h} + b^{(2)}}}{1 + e^{\mathbf{W}^{(2)} \mathbf{h} + b^{(2)}}}.
Exercises 2.1.2
- Convert the training and test arrays in R to
torchtensors. - Train a baseline model for 100 epochs with a single hidden layer of 64 units.
- Extend the baseline by adding a dropout layer (
rate = 0.3) and retrain. - Increase the hidden layer size to 256 units and retrain.
- Add a second hidden layer along with dropout and retrain.
- Train a three-hidden-layer model with 256 units per layer and dropout (0.3).
- Use PCA-transformed features as input and train a model with 256 hidden units.
- Compare the performance of all models with other machine learning methods.
