Early CV research (before 1980s)
Edge and line detection, Sobel operator (1968)

Digit recognition, N-tuple method (1959)
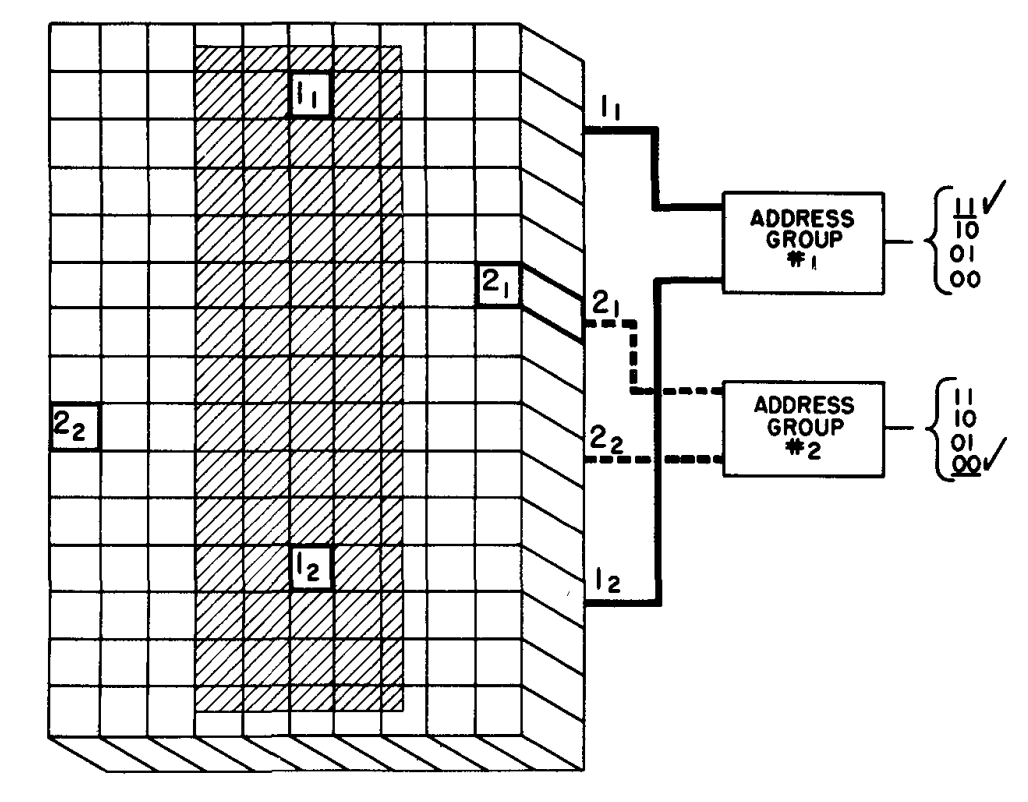
Image segmentation, recursive region splitting (1978)

Image classification, texture analysis (1973)

Rise of CNN (1980s - 1990s)
Document recognition, LeNet-5 (1998)
Face detection (1998)

Lung nodule detection (1995)
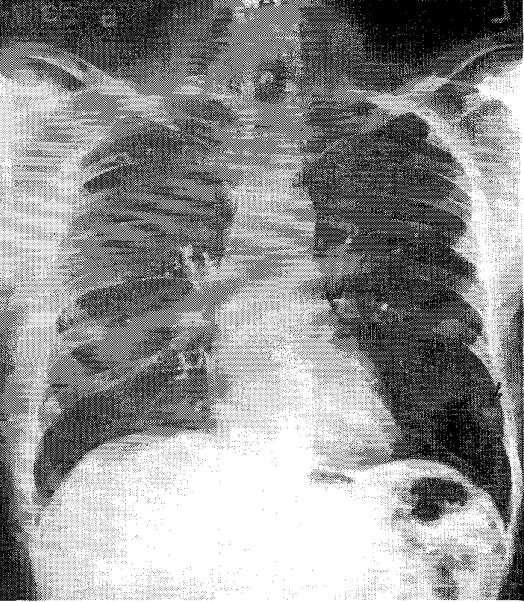
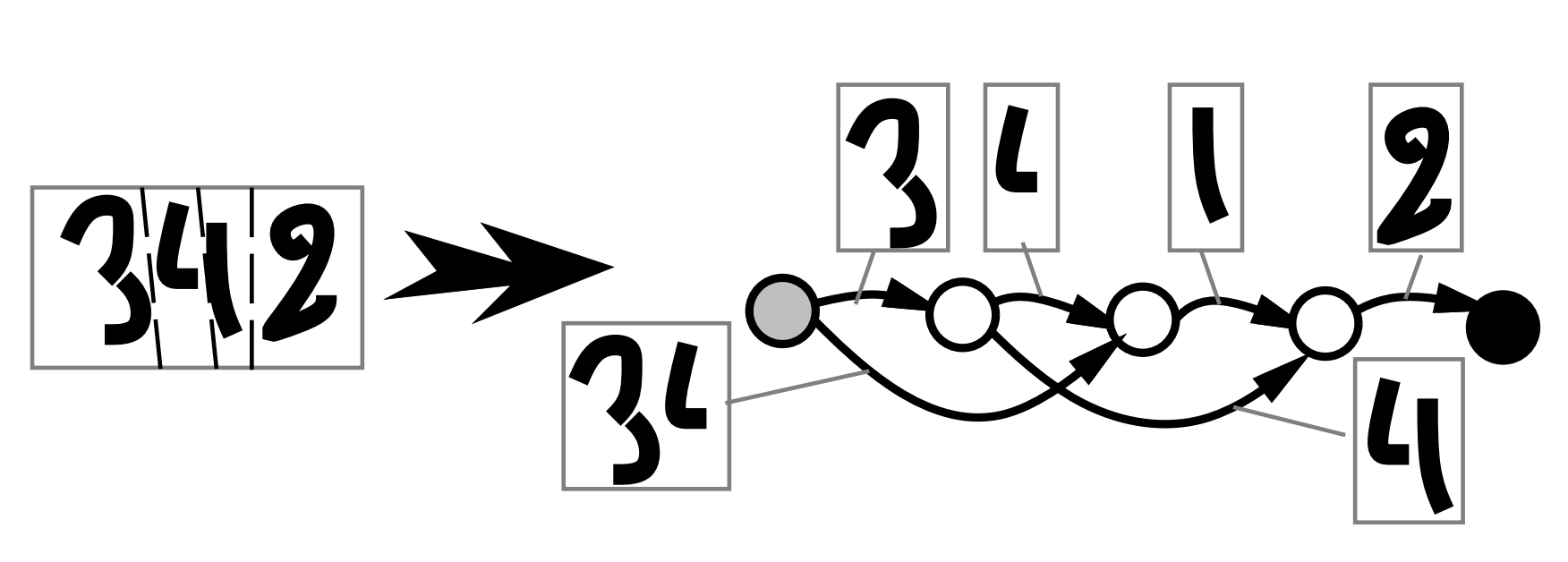
Image segmentation, Cresceptron (1992)

Feature descriptors era (2000s)
Scale Invariant Feature Transform (2004)

Histograms of Oriented Gradients (2005)

Bag of visual words (2004)

Speeded up robust features (2006)
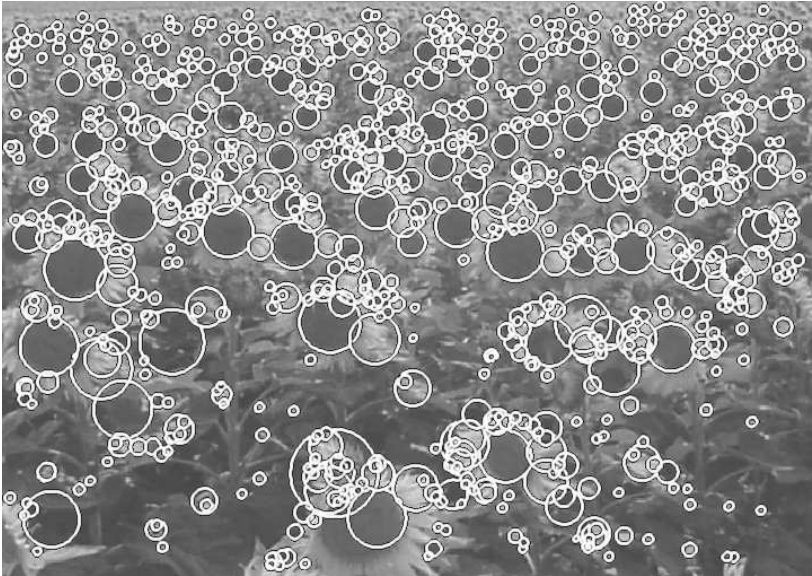
CNN deep learning era (2010s)
Image classification, AlexNet (2012)
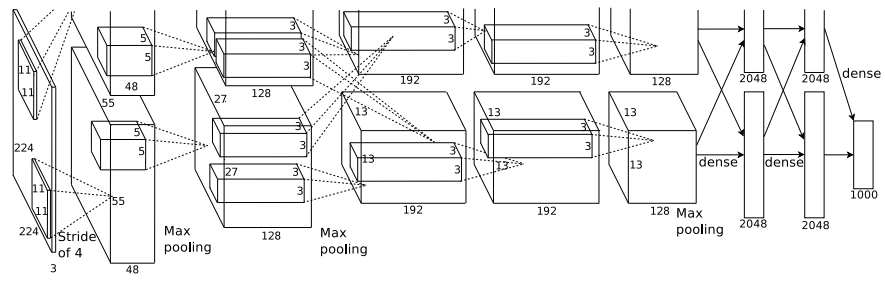
Object detection, R-CNN (2015)
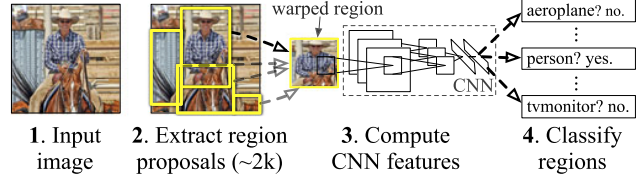
Image segmentation, Fully Convolutional Network (2015)
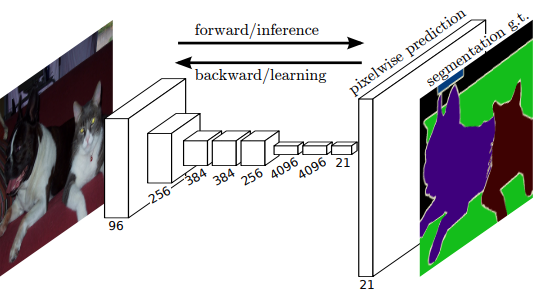
Image generation, Generative Adversarial Nets (2014)

Transformer era (2020s)
Image classification, Vision Transformer (2020)
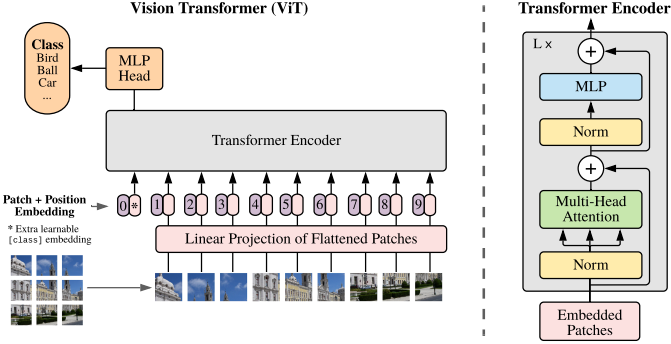
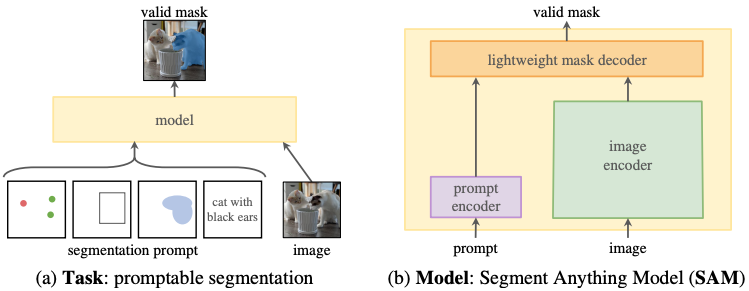
Image segmentation, Segment Anything Model (2023)
Text-to-Image generation, Latent Diffusion Model (2022)

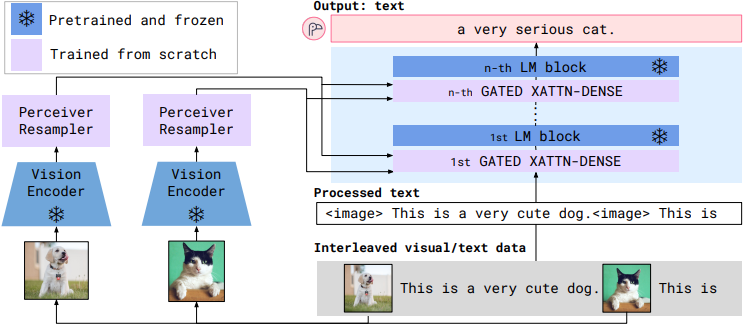
Vision question answering, Visual Language Model (2022)
![]() Theano (2010 - 2017)
Theano (2010 - 2017)
 Theano (2010 - 2017)
Theano (2010 - 2017)- Widely used in the early 2010s for neural network research
- Forks:
- Theano-PyMC: Maintained for probabilistic programming
- PyTensor: Actively maintained, modernised successor with GPU and symbolic support
![]() Caffe (2013 - 2018)
Caffe (2013 - 2018)
 Caffe (2013 - 2018)
Caffe (2013 - 2018)- Dominated computer vision research and industry applications (2013 - 2016)
- Forks:
- Caffe2: Facebook’s production-focused successor (2017)
- OpenCaffe: Community maintenance efforts
- Merged into PyTorch ecosystem (2018)
![]() CNTK (2015 - 2019)
CNTK (2015 - 2019)
 CNTK (2015 - 2019)
CNTK (2015 - 2019)- Strong performance in speech recognition and reinforcement learning
- Legacy:
- Archived: Code available but no active development
- ONNX: Microsoft’s contributions live on in the Open Neural Network Exchange format
- Users migrated primarily to PyTorch and TensorFlow
![]() TensorFlow (2015 - present)
TensorFlow (2015 - present)
 TensorFlow (2015 - present)
TensorFlow (2015 - present)- Dominated industry and research (2016 - present), stable v1.0.0 in 2017
- Current Status:
- TensorFlow 2.x: Actively maintained with Keras as official high-level API
- TensorFlow Lite: Mobile and embedded deployment
- TensorFlow.js: Browser-based machine learning
![]() Keras (2015 - present)
Keras (2015 - present)
 Keras (2015 - present)
Keras (2015 - present)- High-level, user-friendly API designed to run on top of TensorFlow, Theano, or CNTK with a focus on fast experimentation
- Became the most popular high-level neural networks API (2015 - 2019)
- Current Status:
- tf.keras: Integrated into TensorFlow 2.0 as default API
- Keras 3.0 (2023): Multi-backend support (TensorFlow, JAX, PyTorch)
- Actively maintained by Google and the community
![]() PyTorch (2017 - present)
PyTorch (2017 - present)
 PyTorch (2017 - present)
PyTorch (2017 - present)- Rapidly gained popularity in research community, absorbed Caffe2 (2018)
- PyTorch Foundation: Established under Linux Foundation (September 2022)
- Current Status:
- Dominates research: ~95% market share with TensorFlow
- torchvision, torchaudio, torchtext: Rich ecosystem of domain libraries
![]() JAX (2018 - present)
JAX (2018 - present)
 JAX (2018 - present)
JAX (2018 - present)- Not a traditional DL framework — a numerical computing library with autodiff
- Growing adoption in research, especially at Google Brain and DeepMind
- Current Status:
- Actively maintained by Google Research
- Focus: Advanced research, scientific computing, and custom architectures
Choice for this Workshop
